

Google étant la principale porte d’entrée dans « l’Internet-monde » pour une large majorité des internautes du monde, j’ai cherché à savoir ce qu’on pouvait trouver dans les titres de pages Web renvoyés par Google (toutes sources confondues) dans lesquels les termes « femme(s) » ou « filles(s) co-apparaissent avec des références explicites au « Burkina Faso » ou à la « Côte d’Ivoire ». L’analyse de deux corpus pertinemment constitués à cet égard (corpus dénommés « Femme(s)/Fille(s)_BF » et « Femme(s)/Fille(s)_CI ») m’autorise les observations et commentaires ci-après.

Pour le corpus « Femmes/Filles_BF », le graphique N°1 montre qu’il marque une présence remarquable de la thématique « rencontre » (en ligne notamment) : « rencontrer des filles au Burkina Faso » ; « Rencontre des femmes célibataires dans le pays Burkina Faso sur Jecontacte, le site vraiment gratuit » ; « www.solarski.eu/pages/site-rencontre-femmes-burkinabe » ; etc. Telles sont quelques exemples de propositions d’espace Internet de « rencontre » inscrites dans ce corpus.
Est-ce à dire que si on lance sur Google les requêtes « femme(s) » associées à « burkinabè »/« Burkina » ou « fille(s) » associées à « burkinabè »/ « Burkina » on tombera tout de suite sur des sites de rencontre dans les premiers résultats affichés ? Pas forcément, mais on comprendra pourquoi dans la suite de l’article.
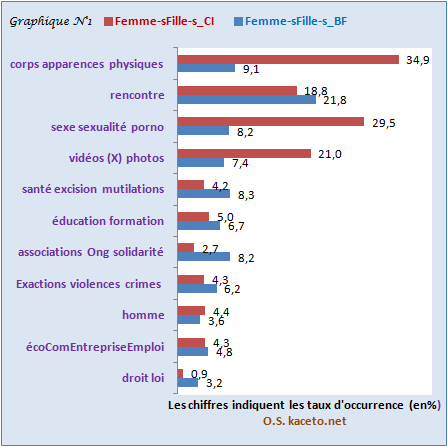
Par ailleurs, notons que le corpus « Femmes/Filles_BF » surclasse le corpus « Femmes/Filles_CI » quant aux références aux thématiques suivantes : « Associations, Ong, Solidarité », « Santé, Excisions, Mutilations » (rappelons tout de même qu’en novembre 1996, le Burkina s’est doté d’une loi condamnant et réprimant la pratique de l’excision), « Education et Formation » (des filles notamment), « Exactions, Violences et Crimes » (dont les femmes et les filles sont trop souvent victimes) et « Droit, Loi » (fort heureusement, en septembre 2015, le parlement intérimaire du Burkina Faso a adopté une loi portant « prévention, répression des violences contre les filles et les femmes… ». Reste à voir si elle est réellement appliquée dans toute sa rigueur…).
Pour le corpus « Femmes/Filles_CI », quatre (4) thématiques sont clairement prégnantes : comme dans le corpus « Femmes/Filles_BF », on retrouve ici aussi la thématique de la « rencontre » (en ligne essentiellement). Mais à cela s’ajoutent trois autres thématiques que sont : La thématique « sexe, pornographie, prostitution » ; celle du « corps et autres apparences physiques » (« grosses fesses », « gros seins », « belles filles », « femme nue », « black », « poilues », etc.) et enfin, celle relative aux « vidéos (« X » essentiellement) et photos ».
Rassurez-vous, on ne confondra pas ici la « présence » dans les résultats de recherche avec la « visibilité ». En effet, comme je le disais tantôt à propos de la référence à la thématique « rencontre », ce n’est pas parce qu’une thématique est fortement présente dans un corpus significatif de résultats de recherche renvoyés par un moteur de recherche qu’elle occupe les premières places dans la file de ces mêmes résultats. Les graphiques N°2 et N°3 permettent de confirmer mon propos.

Je me garderai de vous perdre dans les méandres de l’approche technique. Mais sachez simplement que l’ensemble des résultats de recherche, minutieusement recueillis suite à chaque requête pertinente adressée à Google pour les besoins de l’analyse, a été divisé en trois « secteurs » contenant un volume égal de données textuelles : un secteur « Début des résultats Google » (« Début_RG » sur les graphiques) ; un secteur « Milieu des résultats Google » (« Milieu_RG » sur les graphiques) et un secteur « Fin des résultats Google » (« Fin_RG » sur les graphiques). J’ai ensuite calculé le taux d’apparition de chaque thématique à l’intérieur de chacun des trois secteurs. Cette technique permet de construire des histogrammes de la répartition des thématiques-cibles dans la file des résultats de Google. Je me contenterai ici de l’appliquer au corpus « Femmes/Filles _CI » (« CI » pour Côte d’Ivoire) pour ma petite démonstration.
Le graphique N°2 présente l’histogramme de répartition des quatre références thématiques les plus présentes que sont « rencontre », « sexe, prostitution, pornographie », « corps et apparences physiques » et « vidéos (X), photos ». Les chiffres indiquent le taux d’apparition (ici en %) de ces thématiques dans chaque secteur (les chiffres les plus bas sont indistincts sur les graphiques, mais ça ne gêne pas la lecture). Constat : ces quatre thématiques-là sont significativement plus concentrées en queue de file (3ème secteur) des résultats Google qu’en début (1er secteur).
Le graphique N°3 montre clairement cinq thématiques qui, bien que moins prégnantes que celles du graphique N°2, sont nettement plus concentrées en début de file (1er secteur) des résultats Google qu’en fin de file (3ème secteur). Ce sont : « associations, Ong, solidarité » ; « éducation, formation » ; « santé, excision, mutilations » ; « exactions, violences, crimes » et « économie, commerce, emploi »
Ousmane Sawadogo.
Expert-Consultant : Text Mining et Web Content Mining










Recent Comments
1 Messages
Autour des mots : Quand « femme(s) » ou « fille(s) » apparaissent dans les titres de pages Web explicitement reliées au Burkina Faso ou à la Côte d’Ivoire…, TAPSOBA DESIRE | 11 juillet 2016 - 12:35 1
J’ai lu l’article et j’avoue que je ne prêtait pas du tout attention à cet aspect des informations recueillies sur le Web ! C’est très intéressant de savoir ce qui apparaît en effet comme thématique dans la file des résultats lorsqu’on lance des recherches sur Google. Je suis pas étonné que le thème de la rencontre soit récurrent sous une forme ou une autre dans la mesure la toile est devenu pratiquement le moyen le plus simple, à bas coût ( d’investissement personnel ) pour faire des rencontres.
Un message, un commentaire ?